


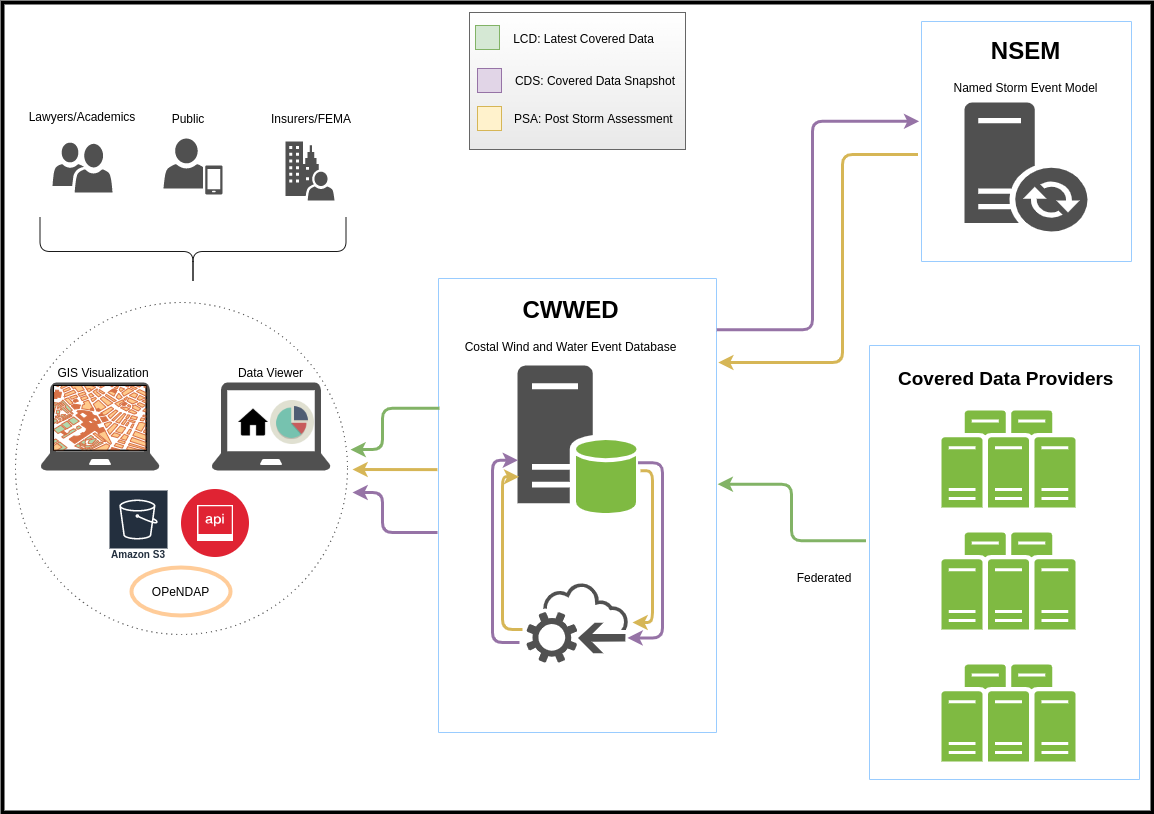
Coastal Wind and Water Event Database (CWWED)
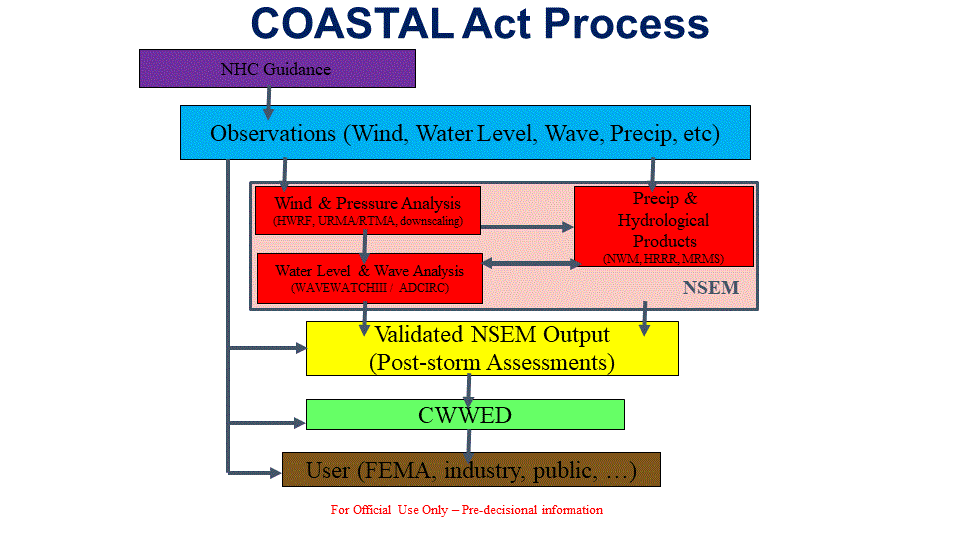
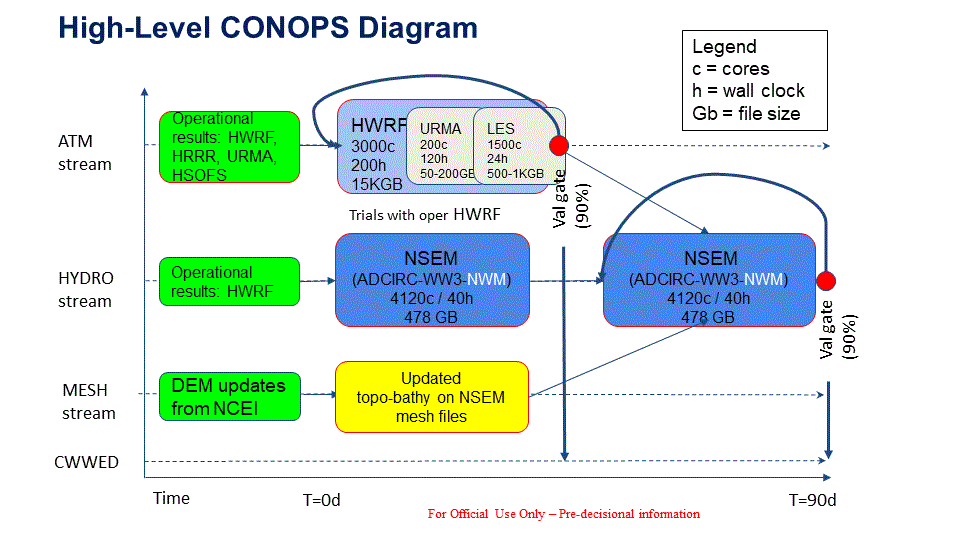
The CWWED will serve as an interactive database that provides access to all “Covered Data”, both by the Named Storm Event Model (NSEM) as well as relevant stakeholders, and serves as an accessible repository for the NSEM output so it can be referenced by FEMA and all relevant stakeholders. To ensure full interoperability with both Covered Data sources as well as the NSEM, it is critical that the CWWED be developed and configured concurrently with the development of the NSEM. In order to achieve this integrated functionality, several things must happen. First, the database structure itself must be developed as a federated database environment. It must then be populated by indexing all existing Covered Data sources and developing (Application Programming Interfaces (APIs) that facilitate the seamless and high-speed transfer, reformatting, and packaging of Covered Data from the data sources to the requestor (e.g., NSEM). As a “federated” database, the CWWED will not house any covered data itself, but rather will act as a virtual database, providing real-time access to covered data as though they were physically housed within the database itself. However, this may require the negotiation and implementation of data sharing agreements or service level agreements between NOAA and external Covered Data sources. The output from the NSEM, while also flowing through the CWWED, would be physically archived on servers at the NOAA National Centers for Environmental Information (NCEI), unless an alternative archival repository is identified for this purpose. When properly configured, this distinction is transparent to users. To ensure that the NSEM is able to request and retrieve all required covered data from the CWWED, and that the CWWED can, an API needs to be developed that intrinsically links the NSEM to the CWWED.
CWWE DATABASE SCHEMATIC
{kind=link}
{kind=link}